The many vision features of Cognitive Services
Monday, 06 June 2016
Microsoft Cognitive Services is a set of APIs that enable developers of any platform or language to add machine learning smarts to their applications. In this article, well explore the many features of the Vision family of APIs
#cognitive-services#computer-vision
This article was published at GitHub. It is open source and you can make edits, comments etc.
Microsoft Cognitive Services is a set of 21 REST APIs that enable developers of any platform or language to add machine learning smarts to their applications.
Whilst there are 21 APIs, many of the APIs have several distinct functions within them. For example, the Computer Vision API facilitates the following capabilities:
- Analyse an image: Gives information about the content of the image such as identifying colour schemes, objects, adult content
- Recognise celebrities: Identify celebrities within an image
- Read text in images: Recognises text embedded within an image and returns it as text
- Generate a thumbnail: Smartly resizes an image based on the area of interest
You would never assume that the Computer Vision API has all of these distinct but powerful capabilities from its name. But it does and it is easy to overlook a feature that might take your application to the next level because you never knew it was there.
This article is part 1 of a series. In the series, I'll provide a very brief overview of each individual function across all of the Cognitive APIs. This should be your 'go to' article if you've ever asked yourself "I wonder if Microsoft Cognitive can do ....". For this article, I'll focus just on the Vision APIs. Speech, Language, Knowledge and Search APIs will be covered in subsequent articles.
Just so you know ... some of the text in this article has been extracted from the Microsoft Cognitive Services website but I've added to it and re-worded it where i think it makes sense.
Computer Vision
https://www.microsoft.com/cognitive-services/en-us/computer-vision-api
Extracts rich information from images to categorize and process visual data—and protect your users from unwanted content.
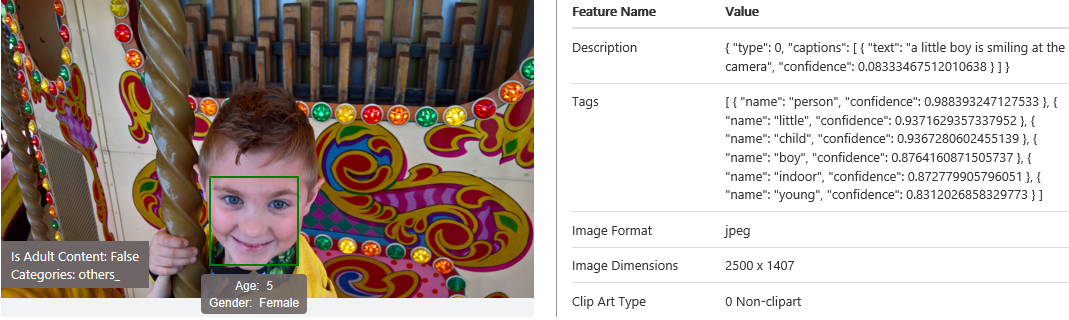
- Analyze an image: This feature returns information about visual content found in an image. Use tagging, descriptions and domain-specific models to identify content and label it with confidence. Apply the adult/racy settings to enable automated restriction of adult content. provides a description of the image and identifies keywords, image format, dimensions, clip art type, line drawing type, black and white images, adult content, categories, faces and dominant colours. There are two API functions called POST Analyze Image and POST Describe Image
- Recognize celebrities: The Celebrity Model is an example of Domain Specific Models. Our new celebrity recognition model recognizes 200K celebrities from business, politics, sports and entertainment around the World. Domain-specific models is a continuously evolving feature within Computer Vision API. There are two API functions called GET List Domain Specific Models and POST Recognize Domain Specific Content
- Read text in images: Optical Character Recognition (OCR) detects text in an image and extracts the recognized words into a machine-readable character stream. Analyze images to detect embedded text, generate character streams and enable searching. Allow users to take photos of text instead of copying to save time and effort. There are two API functions POST OCR and POST Tag Image
- Generate a thumbnail: Generate a high quality storage-efficient thumbnail based on any input image. Use thumbnail generation to modify images to best suit your needs for size, shape and style. Apply smart cropping to generate thumbnails that differ from the aspect ratio of your original image, yet preserve the region of interest. There is a single API function POST Get Thumbnail
Emotion
https://www.microsoft.com/cognitive-services/en-us/emotion-api
The Emotion API takes an facial expression in an image as an input, and returns the confidence across a set of emotions for each face in the image, as well as bounding box for the face, using the Face API. The emotions detected are anger, contempt, disgust, fear, happiness, neutral, sadness, and surprise.
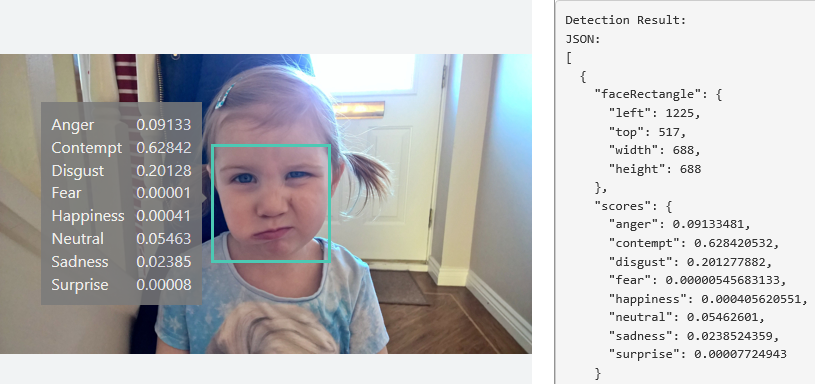
- Emotion Recognition: This features takes an image (a link or a binary stream) containing a human face and returns an analysis of the emotions being exhibited. There are two API functions called POST Emotion Recognition which will identify faces automatically and POST Emotion Recognition with Face Rectangles which allows face rectangles to be sent with the request. This is useful if you are using the Face API to identify particular faces
- Emotion Recognition in Video: This features takes a video containing human faces and returns an analysis of the emotions being exhibited. The video is posted with one request and then the resulted are obtained by a separate request after the video has been processed. There are two API functions called POST Emotion Recognition in Video which is where you'd post a video to the API and GET Recognition in Video Operation Result which is where the result would be obtained. See How to Call Emotion API for Video for more details
Face
https://www.microsoft.com/cognitive-services/en-us/face-api
The Face API can detect human faces in an image and return a plethora of interesting data about them. This facilitates a wide range of features including detection, verification, grouping, similar face matching.
There are several entity concepts in the Face API, they include:
- Face: An anonymous human face within an image
- Face List: A list of up to 64 persisted face objects that you can build up over time using the
faceIdof the Face object - Person: A Face which has been attributed with a
nameand/oruserDatafor purposes of verification and identity - Person Group: A list of person objects which must be trained. Once train it can be used with the verification and identification APIs
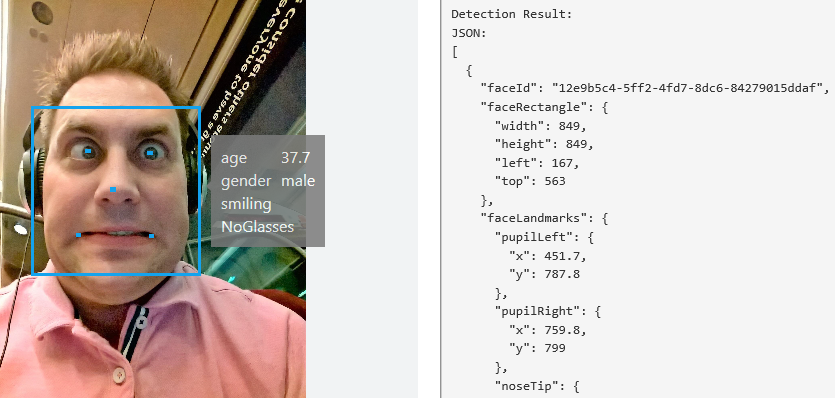
The individual functions within the Face API are as follows:
- Face Detection: This feature detects up to 64 human faces in an image and returns each individual Face. This includes a face bounding rectangle, a series of points that identify the face in the image. It also returns face landmarks, a series of 27 points within the face rectangle identifying important features such as pupils, eyebrows, nose etc. You will also get a series of Face Attributes which includes things like age, gender, smile intensity, facial hair, head pose and glasses. You can also optionally request a
FaceIdto be used with Face List and Person objects. There is a single API function POST Face Detect - Face Verification: This feature assess the likelihood of two faces being the same person. The API will return a confidence score about how likely it is that the two faces belong to one person. There is a single API function POST Face verify
- Face Identification: This feature uses the Person Group entity to scan images for similar faces. There is a single API function POST Face Identify. However this API also depends an array of
FaceId(via the POST Face Detect) andPersonGroupId(via the PUT Create a Person Group). - Similar Face Searching: Find similar looking faces for a query face from a list of candidate faces (given by a face list or a face ID array) and return similar face IDs ranked by similarity. The candidate face list has a limitation of 1000 faces. There is a single API function POST Face - Find Similar. This API requires a
FaceId(via the POST Face Detect), aFaceListId(via the GET Face List or PUT Create a Face List) and an array ofFaceIdrepresenting the candidates faces which can be obtained from POST Face Detect. - Face Grouping: Organize up to 1000 unidentified faces together into groups, based on their visual similarity. There is a single API function GET Face - Group which requires a list of
FaceIdwhich can be obtained from POST Face Detect.
Video
https://www.microsoft.com/cognitive-services/en-us/video-api
The video provides intelligent video processing, produces stable video output, detects motion, creates intelligent thumbnails, and detects and tracks faces.
Due to the large file size and associated latency with video files, all four functions operate a model whereby a video is POSTed (via a URL or binary) to the API and then processed in the background, no immediate results are given. You can poll for results using the GET Operation Result api and then get the final result using GET Result Video api which will return the processed video file as a binary application/octet-stream.
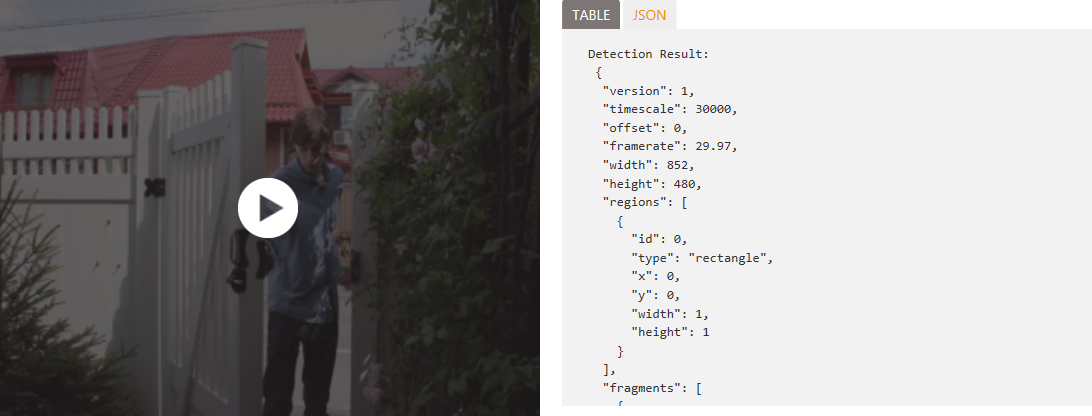
The video api contains the following functions
- Stabilization: Smooth and stabilize shaky video. Given an input video, the service will generate a stabilized version of the video. Great for actions videos taken on devices like GoPro and phones. There is a single API function POST Stabilization which operates a job model where the result is obtained later using GET - Operation Result and GET - Result Video
- Face detection and tracking: Detect and track up to 64 faces in videos. This service will analyze the video inputted and output metadata for faces and location of the faces within the video frames. There is a single API function POST - Face Detection and Tracking which operates a job model where the result is obtained later using GET - Operation Result and GET - Result Video
- Motion detection: Detects motion in a video, and returns the frame and duration of the motion that was captured. There is a single API function POST - Motion Detection which operates a job model where the result is obtained later using GET - Operation Result and GET - Result Video
- Video thumbnail: Generates a motion thumbnail from a video. The Video Thumbnail API provides an automatic summary for videos to let people see a preview or snapshot quickly. Selection of scenes from a video create a preview in form of a short video. There is a single API function POST - Thumbnail which operates a job model where the result is obtained later using GET - Operation Result and GET - Result Video
In summary
We've covered 15 individual functions which span 4 APIs in this article.
This is just the 'Vision' category in the wider Microsoft Cognitive Services suite.
In forthcoming articles, I'll cover the Speech, Language, Knowledge and Search APIs and their individual functions in a similar level of detail ... unless no-one reads or comments on this, in which case I shan't bother! :)
Got a comment?
All my articles are written and managed as Markdown files on GitHub.
Please add an issue or submit a pull request if something is not right on this article or you have a comment.
If you'd like to simply say "thanks", then please send me a .